


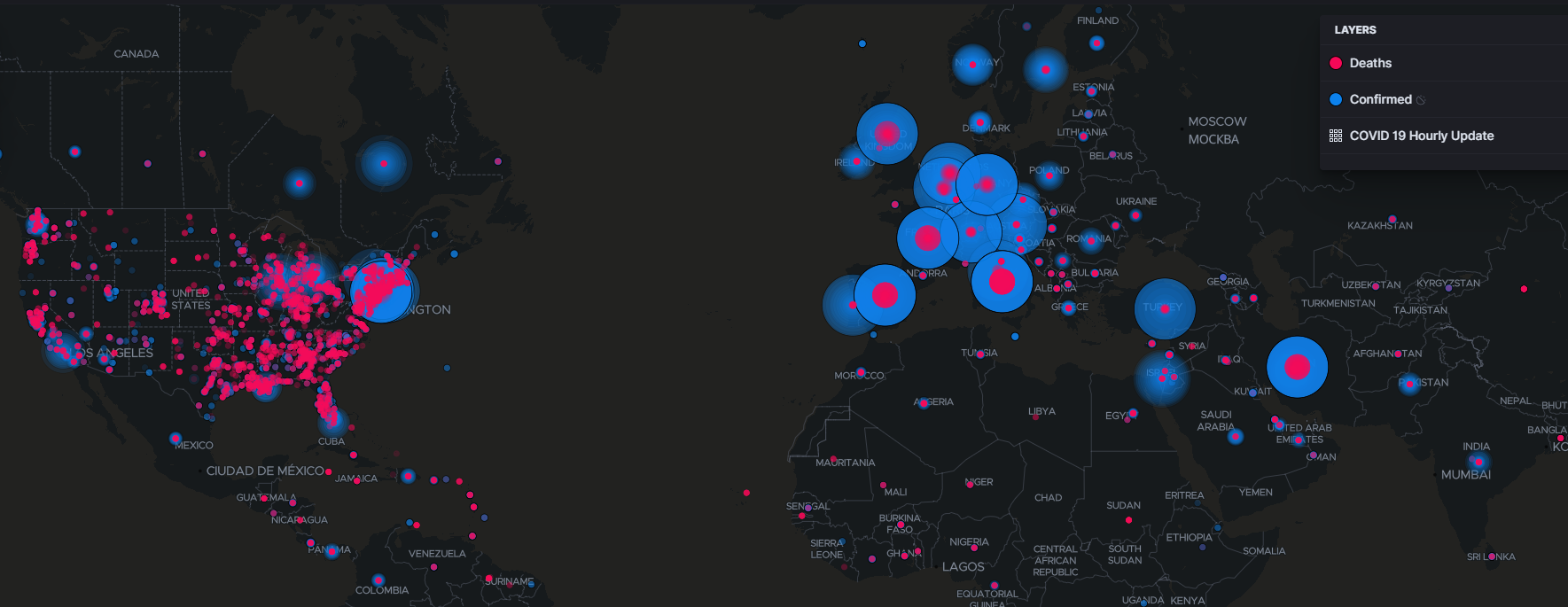
We launched an interactive Kibana dashboard for the COVID-19 outbreak. You can use the dashboard for filtering and comparing COVID-19 data from different countries, regions and counties enabling you to run your own analysis of the outbreak.
In part 1 of this blog post we offered detailed steps on how to import COVID-19 data into your elasticsearch cluster together with a pre-built dashboard for analysis. In this second part of the blog post we will show you how to correlate and enrich this data set with other data sets for your own business use cases.
If you are interested to see how Siscale can help you during these uncertain times >check out this page. For more information on correlating and enriching COVID-19 data read on!
What is correlation and enrichment
Before getting started let’s clarify what exactly do we mean through correlation and enrichment.
Correlation – renaming certain field names to coincide with the names of similar fields in other data sets. This essentially allows us to add 2 different data sets in a single dashboard and apply filters to fields with the same name in order to correlate events.
Enrichment – add additional information in the form of new fields to an already existing data set based on a common identifier. This will allow us to add COVID-19 data to existing data sets or vice-versa. We will explore 2 ways of enriching your data in this blog post: from an already existing index in your elasticsearch cluster and from a CSV file.
Renaming fields for cross-dataset correlation
In order to rename fields we need to add an additional segment to the ingest pipeline. The below snippet contains fields from the COVID-19 data set. The fields on the left are the original names in the dataset while the fields on the right (just after the “=>” symbol) are the new names given to the fields.
You can change the right side fields to any name you want. However in order to be able to correlate events cross-datasets the new names given to your fields should be identical to the field names in your other dataset.
#Rename the fields on the right if you want to correlate with other datasets
#Add below segment just before the Output section of the pipeline for which you want to change the field names
mutate {
rename => {
"province_state" => "province_state"
"country_region" => "country_region"
"admin2" => "county"
"fips" => "fips"
"confirmed" => "confirmed"
"deaths" => "deaths"
"recovered" => "recovered"
"active" => "active"
"[location][lat]" => "[location][lat]"
"[location][lon]" => "[location][lon]"
"last_update" => "last_update"
"last_process" => "last_process"
"combined_key" => "combined_key"
"ratio_deaths_to_confirmed" => "ratio_deaths_to_confirmed"
"ratio_recovered_to_confirmed" => "ratio_recovered_to_confirmed"
"ratio_deaths_to_recovered" => "ratio_deaths_to_recovered"
"unique_id" => "unique_id"
}
}#end mutate
Enriching events using existing elasticsearch data
In order to enrich events from an existing elasticsearch index we will need to use a unique identifier between the two indices (the index we’re looking to enrich and the index from where we will be pulling the data). The unique identifier can be a field which has the same value in both indices. Let’s look at an example:
Assume events in the following form:
{
"@timestamp" : ""
"product_information" : { … }
"command_id" : "XZFGR3424",
"destination" : {
"address" : "105-59 Edgewater Dr Middletown, NY 10940",
"country" : "US",
"state" : "NY",
"county" : "Orange"
}
}
In order to enrich the above event with COVID-19 data we can use the county and state fields to match events in the COVID-19 index. This can be achieved by adding the following code segment to the pipeline of the index you want to enrich in the filter section.
filter {
#......
#Other filters here
#......
elasticsearch {
#Index containing COVID-19 data
index => "covid-19-live-update"
hosts => -
user => -
password => -
#The query used to match ES data (fields 'county' and 'province_state')
#With data from the incoming ('destination.county' and 'destination.province_state' - %{[field]} will be replaced by the value of 'field')
#See (https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-query-string-query.html)
query => "(county:%{[destination][county]}) AND (province_state:%{[destination][state]})"
enable_sort => true
#Get the latest report for that region
sort => "@timestamp:desc"
#Copy the fields from ES ('confirmed', 'deaths', 'recovered') to the incoming event and rename them as specified
fields => {
"confirmed" => "[destination][cases][confirmed]"
"deaths" => "[destination][cases][deaths]"
"recovered" => "[destination][cases][recovered]"
"@timestamp" => "[destination][cases][report_date]"
}
}
}
Now events matching on the county and state fields will be enriched with the latest update of COVID-19 data. Looking at our example the new event will look like this:
{
"command_id" => "XZFGR3424",
"destination" => {
"state" => "New York",
"address" => "105-59 Edgewater Dr Middletown, NY 10940",
"county" => "Orange",
"country" => "US",
"cases" => {
"deaths" => "1",
"report_date" => "2020-03-25T00:00:00.000Z",
"recovered" => "0",
"confirmed" => "638"
}
}
As you can see the event has 4 new fields related to COVID-19 data: cases.deaths, cases.report_date, cases.recovered and cases.confirmed. The values of these fields will be specific for the Orange county in the state of New York because these are the fields used to match the events.
Enriching events using csvenrich filter plugin
Before starting you will need to install the csvenrich plugin. The plugin can be found here: >https://github.com/sarwarbhuiyan/logstash-filter-csvenrich
The principle behind enriching events using the csvenrich plugin is similar to the enrichment using already existing elasticsearch indices. We will use a unique identifier in order to match events. Let’s look at an example.
Assume a CSV file as follows:
country_region,state_province,county,site,address,lat,long
US,NY,Nassau,NY_GARDEN_CITY,"625 South St, Garden City, NY 11530 ",40.735995,-73.603024
US,NY,New York,NY_CENTRAL_PARK_S,"220 Central Park S, New York, NY 10019",40.767185,-73.98016
US,NY,Rockland,NY_SPRING_VALLEY,"Maple Ave, Spring Valley, NY 10977",41.117327,-74.04389
US,CA,San Benito,CA_SAN_BENITO,"429-401 San Benito St, Hollister, CA 95023",36.852203,-121.402051
US,CA,San Francisco,CA_SAN_FRANCISCO,"The Embarcadero S, San Francisco, CA 94105",37.789698,-122.388808
In order to enrich our data set with information from the above CSV (site name for example) we need to add the following code segment to the pipeline of the index we want to enrich in the filter section.
if [county] {
csvenrich {
#Path to the CSV used for enrichment
file => "/etc/logstash/mock_csv.csv"
#Name of the column in the CSV used to match the event
key_col => "county"
#Name of the column in the event used to match the CSV data
lookup_col => "county"
#On the left the fields we want to enrich from the CSV. On the right the name of the fields in the index
map_field => {
"site" => "[site][name]"
"address" => "[site][address]"
"lat" => "[site][location][lat]"
"long" => "[site][location][lon]"
}
}
Using the above in the index pipeline will add the following new fields: site.name, site.address, site.location.lat and site.location.lon to the data set. The values of these fields will be specific for matches made on the “county” field (Orange county data will be different from Nassau county for example).
Business use cases suggestions
- Correlate COVID-19 evolution with remote access usage for work-from-home scenarios
- Correlate COVID-19 evolution with business metrics for automated reporting
- Geo-spacial analysis of COVID-19 data to adjust transportation routes
- Real-time monitoring of COVID-19 evolution in business context
- Correlate COVID-19 data with patient data to determine risks based on passed known-conditions
If you require help or assistance with this process please reach out to us at contact@siscale.com

