


In the world of Elasticsearch the subject of shards is a highly debated one and for good reason. Setting up a good sharding strategy appropriate to your use case is essential if you don’t want to struggle with cluster stability, high resource consumption or query performance, to name a few.
But first let’s see what is a shard and what is its purpose.
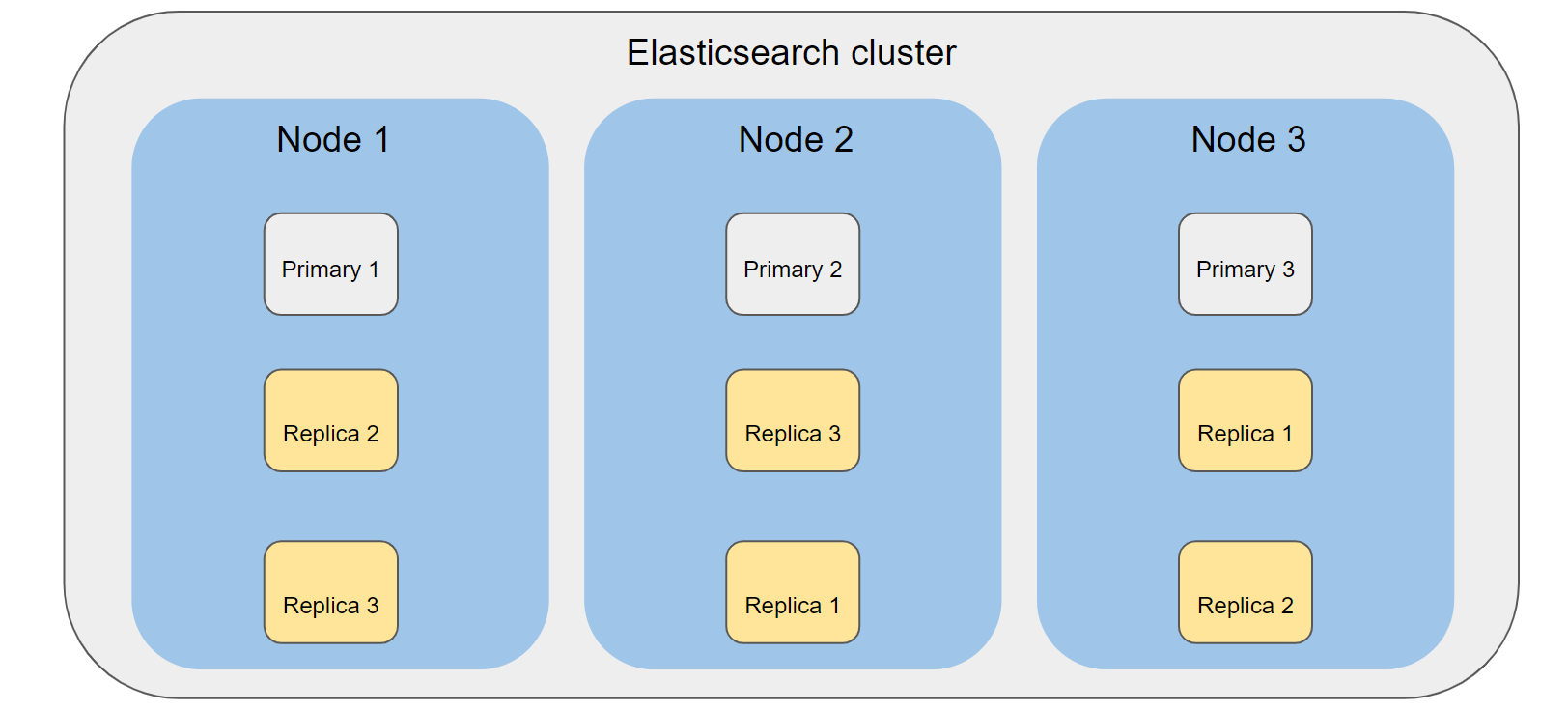
Elasticsearch is actually built on top of Lucene, which is a text search engine and every Elasticsearch shard represents a Lucene index. You can think of shards as having your data spread out in several different places at the same time which Elasticsearch manages across several nodes.
There are two types of shards: primary and replica. The role of primary shards is to hold part of the data stored into an index and each primary shard can be queried at the same time in order to retrieve the data, which is one of the reasons Elasticsearch is so fast. Primary shards are set for each index at creation and their number can be changed afterwards using the _shrink API however this can only be done when data is no longer being written into the index.
Replica shards are simple copies of the data stored on the primary shards. Their role is to offer high availability to the data as well as handle search requests. The main reason to have replica shards is to have data redundancy so in the case a primary node holding a primary shard fails to start or the shard itself gets corrupted and can no longer be used a replica for that shard becomes a primary shard and all data becomes available once more.
Observation: the number of replica shards acts as a multiplier for the number of primary shards. That means that if you have an index with 3 primary shards and 2 replicas each primary shard will have 2 replicas for a total of 9 shards (3 primary and 6 replicas).
Optimizing for storage
Because Elasticsearch is so good at retrieving data very fast it is common to see very large Elasticsearch clusters holding large quantities of data from several sources and as new use cases become involved and new data is added to the cluster storage becomes an important aspect.
Shards have a direct impact on storage requirements for any Elasticsearch cluster and more specifically replica shards. Remember that the number of replica shards is a multiplier for each primary meaning that the required storage to hold your “original” data increases as you set up more replica shards for your index.
Let’s say you have a daily index of 100 GB of data and your index is set to have 4 primary shards and 2 replicas. The 100 GB of data will be split between each primary shard having roughly 25 GB of data for each primary shard. But each primary shard also has 2 replicas which hold copies of the same data bringing your total required disk to 300 GB in order to accommodate this index.
The number of replicas can be reduced in order to have more disk space available to store data however keep in mind that you are trading data redundancy for it. Going back to the previous example let’s see what happens if you reduce the number of replicas to 1. Having a cluster with 4 nodes and the shards spread out between those nodes, in the unlikely event that you have 2 nodes fail which hold both primary shard 1 and replica shard 1 you have data loss.
Observation: the maximum number of replica shards should be kept to a maximum equal to the number of data nodes minus 1. This will ensure that you do not keep a replica shard on the same node as the primary shard.
Optimizing for heap
Balancing the amount of heap for your Elasticsearch cluster is an essential aspect of keeping your cluster in good health. The cluster state, which holds all the metadata for the cluster such as information about shards and indexes, is held in memory in order to be quickly accessible and therefore having a very large cluster state can slow-down the cluster altogether.
The amount of data you can hold on a node will be directly impacted by how much heap you have allocated to that node. It is generally a good idea to keep your shard count to a maximum of 25 per GB of heap you have allocated to your nodes. Having a lower number can help with keeping your cluster in good health while going above the number might result in performance issues.
Keep in mind that Elasticsearch does not force any limit to the number of shards per GB of heap you have allocated so it is a good idea to regularly check that you do not go above 25 shards per GB of heap. Also this rule applies to all shards, both primary and replicas so make sure to check the total number of shards for your indexes.
Optimizing for query performance
Query performance relies first and foremost on the data that is being queried and the query itself. Complex queries over large data sets can result in slower response times compared to simple queries over small data sets, however there are ways to improve this performance by optimizing your shard settings.
When a query is being run it is executed against each shard available for that index. That means that having many shards can result in fast responses, however, having too many tasks running at the same time can slow down the performance of the query. Running the same query against fewer and larger shards will not necessarily be faster either because for each shard the query will have to search through more data although there are fewer tasks running.
As you can see in terms of query performance there needs to be a balance between shard count and shard size. It is a good rule to keep your shard size somewhere between 20GB and 40GB which should offer you a good balance.
Keep in mind when calculating shard size that replica shards are just copies of the primary shards and should not be taken into consideration when dividing your index size. Going back to our example of the daily index with 100 GB of data with 4 primary shards and 2 replicas for a total of 12 shards, you should divide the 100 GB of data to 4 not 12.
Keeping your Elasticsearch cluster optimized is a balancing act and will depend first and foremost on the resources you have available, the data you want to analyze and your use cases. However, the suggestions made in this article will help you keep your cluster in good health and improve performance.
Our final advice to you is to make sure to do regular maintenance and benchmark your cluster to make sure everything is running smoothly.
Want to learn more about how to benchmark your cluster? Get in touch with an expert like Arcanna.ai.

